
도메인 네임과 네임 서버
네트워크상의 어떤 호스트를 특정하기 위해 IP 주소를 사용한다. 하지만 모든 IP 주소를 외울 수도 없을뿐더러, IP 주소는 언제든지 바뀔 수 있기 때문에 모든 IP 주소만으로 통신하는 것도 어렵다.
때문에 일반적으로 사용자는 특정 호스트를 특정하기 위해 IP 주소 보다는, 도메인 네임을 많이 사용한다.
도메인 네임은 ‘www.example.com’, ‘developers.naver.com’ 과 같은 문자열을 의미한다.
네임 서버에서 도메인 네임과 IP 주소를 하나의 쌍으로 관리한다. 네임 서버를 DNS 서버라고도 부른다.
네임서버에 질의하여 도메인 네임을 통해 IP 주소를 알아낼 수 있다.
💡 호스트마다 hosts 파일이라는 것을 가지고 있다. 이 파일엔 도메인 네임과 IP 주소의 대응 관계가 담겨있다. 다만 모든 내용이 적혀 있지는 않다. 모든 도메인과 IP 주소의 대응 관계를 알기 위해선, 네임 서버가 꼭 필요하다.
네임서버는 도메인을 점(.)을 기준으로 계층적으로 분류한다. 최상단에 루트 도메인이 있고, 그 다음 단계로는 최상위 도메인(TLD; Top-Level Domain)이 있으며, 쭉 이어진다.

도메인 이름의 마지막에 적혀있는 부분이 최상위 도메인, 즉 TLD이다. 그보다 더 위로는 루트 도메인이 있으며, 점으로 이루어져 있다. TLD보다 하부에 있는 도메인을 2단계 도메인이라고 하며, 그다음은 3단계 도메인으로 불린다.
도메인은 일반적으로 3~5단계정도이며, ‘www.example.com.’처럼 도메인 네임을 모두 포함하는 도메인 네임을 전체 주소 도메인 네임(FQDN; Fully-Qualified Domain Name)이라고 한다. 이때 마지막 단계의 도메인(예시의 ‘www’)을 호스트 네임이라고도 부른다.
네임 서버는 여러 개 존재하며, 전 세계 여러 군데에 위치해 있다. 이처럼 계층적이고, 분산된 도메인 네임에 대한 관리 체계를 도메인 네임 시스템(Domain Name System), 줄여서 DNS라고 부른다.
서브 도메인이란?
서브 도메인은 다른 도메인이 포함된 도메인을 의미한다. 다음은 google.com의 서브 도메인이다.
- mail.google.com
- www.google.com
- scholar.google.com
- drive.google.com
계층적 네임 서버
IP주소를 모르는 상태에서 도메인 네임에 대응되는 IP 주소를 알아내는 과정을 리졸빙(resolving)이라고 한다.
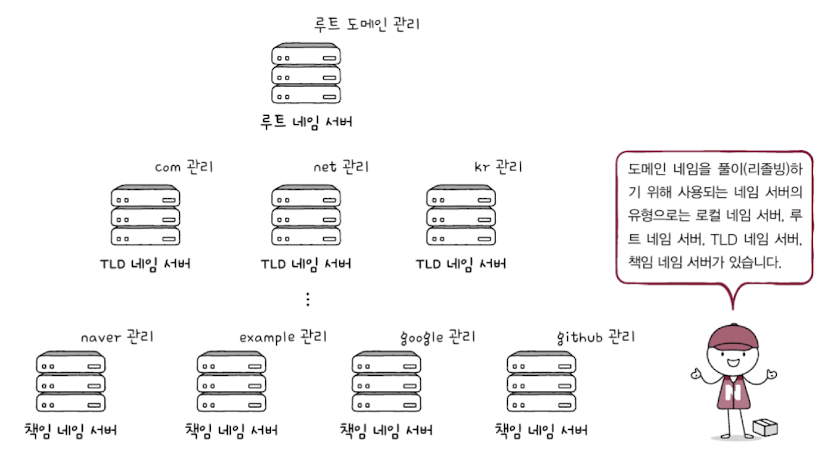
이 과정에서 다양한 네임 서버들이 사용되는데, 중요한 역할을 담당하는 네임 서버의 유형은 크게 네 가지가 있다.
- 로컬 네임 서버
- 클라이언트와 맞닿아 있는 네임 서버. 클라이언트가 리졸빙을 할 때 가장 먼저 찾는 네임 서버이다. 로컬 네임 서버는 JSP에서 할당해 주는 네임 서버주소를 사용하기도 하지만, 공개 DNS 서버를 이용할 수도 있다.
- 클라이언트가 로컬 네임 서버에게 질의했을 때 로컬 네임 서버가 IP 주소를 알고 있다면 IP 주소를 반환하지만, 모른다면 루트 네임 서버에게 질의하게 된다.
- 루트 네임 서버
- 루트 도메인을 관장하는 네임 서버로, 질의에 대해 TLD 네임 서버의 IP 주소를 반환할 수 있다.
- TLD 네임 서버
- TLD를 관리하는 서버로, 질의를 받으면 TLD의 하위 도메인 네임을 관리하는 네임 서버 주소를 반환할 수 있다.
- 책임 네임 서버
- 특정 도메인 영역을 관리하는 네임 서버로, 자신이 관리하는 도메인 영역의 질의에 대해서는 곧바로 답할 수 있는 네임 서버이다. 즉, 마지막으로 질의하는 네임 서버이다. 일반적으로 로컬 네임 서버는 책임 네임 서버로부터 원하는 IP 주소를 얻어낸다.
이처럼 로컬 네임 서버에서부터 책임 네임 서버까지 도달하는 과정을 통해 네임 서버가 계층적인 구조를 띠고 있다는 것을 알 수 있다.
도메인 네임을 리졸빙하는 과정은 크게 재귀적 질의와 반복적 질의라는 두 가지 방법이 있다.
재귀적 질의는 각각의 네임 서버가 다음 네임서버에게 질의를 하고, 질의 결과를 받으면 자신에게 질의한 네임 서버로 결과를 전달한다.

반복적 질의는 로컬 네임 서버가 루트 네임 서버로부터 책임 네임 서버에까지 돌아가며 질의를 한다. 그 뒤 최종 결과를 클라이언트에게 반환한다.
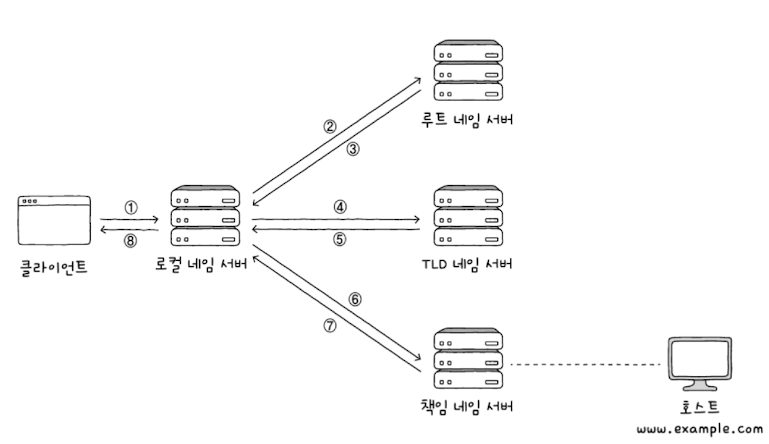
여기에서 알 수 있는 점은 8개의 단계를 거치는 것이 매우 느리며, 루트 네임 서버에 과부하가 생길 수 있다는 점이다.
그래서 실제로는 네임 서버들이 기존에 응답받은 결과를 DNS 캐시에 임시로 저장했다가 추후 같은 질의에 이를 활용할 수 있다. DNS 캐시는 영원히 남아있지 않으며, TTL이라는 값에 따라 소멸한다.
자원을 식별하는 URI
자원이란 네트워크상의 메시지를 통해 주고받는 대상을 의미한다. HTML, 이미지, 동영상 등이 여기에 포함된다.
이런 자원을 주고받으려면 자원을 식별해야 한다. 자원을 식별할 수 있는 정보를 URI(Uniform Resource Identifier)라고 부른다.
자원을 식별하는 방법은 위치를 이용해 식별하는 방법과 이름을 통해 자원을 식별하는 방법이 있다. 위치를 이용해 식별하는 방법을 URL(Uniform Resource Locator)이라 하고, 이름을 통해 자원을 식별하는 방법을 URN(Uniform Resource Name)이라고 한다.
URL
오늘날 자원 식별에 더 많이 사용되는 방법이다.
위와 같은 형식을 띄며, 이 URL 형태는 인터넷 표준 문서(RFC 3986)에서 소개하는 일반적인 URL 표기이다.
- scheme : URL의 첫 부분으로 자원에 접근하는 방식을 의미한다. HTTP를 사용할 땐 http://를 사용하고, HTTPS를 사용할 땐 https://를 사용한다.
- authority : 호스트를 특정할 수 있는 정보로, IP 주소 혹은 도메인 네임이 명시된다. 콜론 뒤에 포트 번호를 덧붙일 수 있다.
- path : 자원이 위치한 경로로, 슬래시를 기준으로 계층적으로 표현된다.
- query : 쿼리 문자열을 통해 요청 메시지를 보낼 때 다양한 정보를 첨부할 수 있다.
- fragment : 자원의 한 조각을 가리키기 위한 정보로, 흔히 HTML 파일과 같은 자원에서 특정 부분을 가리키기 위해 사용된다.
URN
URL은 위치 기반으로 자원을 식별한다. 자원은 언제든지 이동할 수 있기 때문에 유효하지 않을 수도 있다.
반면 URN은 자원에 고유한 이름을 붙이는 이름 기반 식별자이므로, 위치와 무관하게 자원을 식별할 수 있다.
다음은 ISBN이 0451450523인 도서를 나타내는 URN 예시이다.
urn:isbn:0451450523
이와같은 URN을 이용하면 위치나 프로토콜과 무관하게 자원을 식별할 수 있다.
DNS 레코드 타입
네임 서버는 DNS 자원 레코드라 불리는 정보를 저장하고 관리한다. 단순히 DNS 레코드라고도 불린다.
레코드는 도메인 네임을 구입한 뒤 적용시킬 때 자주 접하게 된다. 만약 도메인을 구매하고 IP 주소와 연결시켰을 때, 이를 다른 사용자가 접속하기 위해선 도메인을 네임 서버에 알려야 한다. 그러기 위해선 DNS 레코드에 새로운 레코드를 등록해야 한다.
'도서 정리 > 혼자 공부하는 네트워크' 카테고리의 다른 글
| [혼자 공부하는 네트워크] Chapter 5 - 3 HTTP 헤더와 HTTP 기반 기술 (0) | 2024.08.15 |
|---|---|
| [혼자 공부하는 네트워크] Chapter 5 - 2 HTTP (0) | 2024.08.15 |
| [혼자 공부하는 네트워크] Chapter 4 - 3 TCP의 오류/흐름/혼잡 제어 (0) | 2024.07.28 |
| [혼자 공부하는 네트워크] Chapter 4 - 2 TCP와 UDP (0) | 2024.07.28 |
| [혼자 공부하는 네트워크]Chapter 4 - 1 전송 계층 개요 : IP의 한계와 포트 (0) | 2024.07.28 |